This AgReFed Project is contributed by the Sydney Informatics Hub, The University of Sydney.
![]()
Project summary
The Geodata-Harvester project enables researchers with reusable workflows and provides open-source software for automatic data extraction from a wide range of data sources including spatial-temporal processing. User provided data is auto-completed with a suitable set of spatial- and temporal-aligned covariates as a ready-made dataset for machine learning models or farm inspections. All data layer maps are automatically extracted and aligned for a specific region and time period.
About
There is an enormous amount of national/global space-time data that is free and accessible. Examples are the numerous satellite platforms, weather, soil landscape grid of Australia. Many have a temporal dimension so for any point in Australia you can extract a time series of remote sensing and weather data and soil and terrain site variables. In the case of time series covariates there are a number of post-processing steps that a user can undertake to extract meaning, e.g. temporal means, aggregating in time. All of the above is a non-trivial task and a workflow where a user could enter a point (s) and get a tidy data frame of data cube variables would be a step towards people understanding its value and being able to jumpstart their analysis.
Currently, a researcher must search through several places for these resources. This includes publication search engines, specialist aggregators or repositories (such as AgMIP), R libraries, between statistical packages, GitHub, on the web and through personal contacts. This can be an inefficient use of time, inefficient computations, and missed research output opportunities. The ideal experience for researchers would be to be able to find and extract key foundational datasets (such as climate, soil, and remote sensed data such as vegetation fractional cover) at once given the required spatial and temporal locations for their analysis. The data would then be able to be selected and extracted in the desired format, and stored to either their local desktop, or virtual desktop with access to a high compute workspace. It will be ready for integration with their own data and analysis. Ideally, multiple datasets/spatial layers will be able to be selected, processed and extracted at the one time, for example within a spatial area/polygon and/or temporal range.
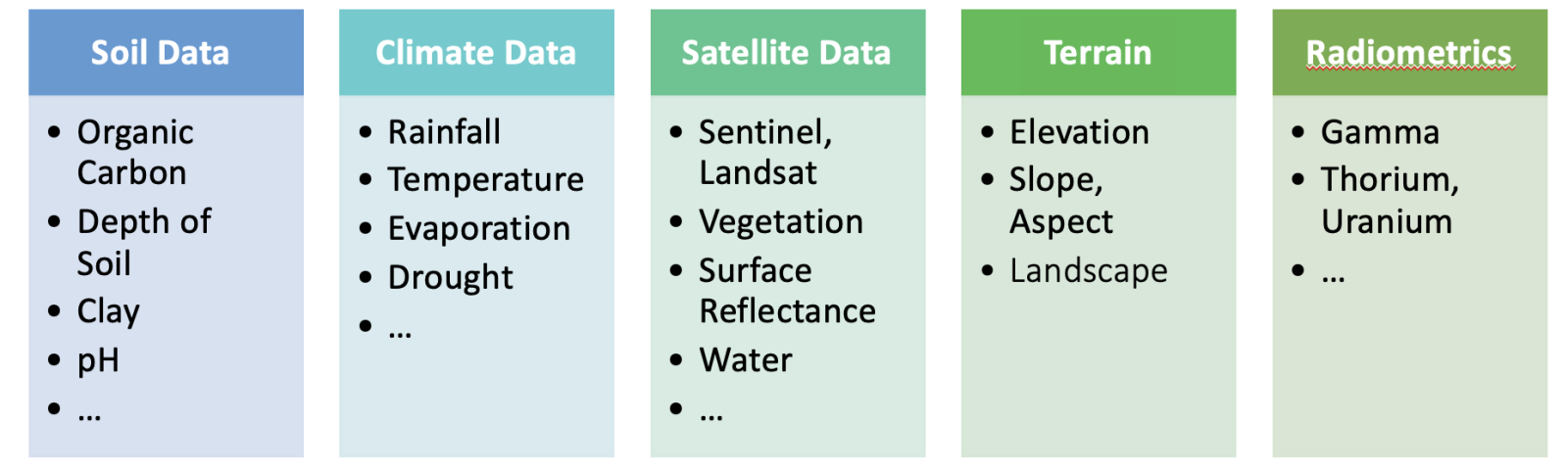
The following data sources are currently integrated:
- Soil and Landscape Grid of Australia (SLGA): 12 different soil properties plus confidence intervals available at 6 depth intervals each.
- SILO Climate Database (Australia): containing continuous daily climate data for Australia from 1889 to present for 19 different climate properties
- National Digital Elevation Model (DEM) 1 Second Hydrologically Enforced, plus functionality to calculate slope and aspect ratio
- Digital Earth Australia (DEA) Geoscience Earth Observations: e.g. Landsat, Sentinel, Surface reflectance and Bare-Earth Maps
- Radiometric Data (Australia)
- Topographic Landscape Data (from SLGA)
- Google Earth Engine (GEE )Integration: e.g. Landsat, Sentinel, NDVI and other index products
More Information and Software Repositories
- Project Homepage
- Python Github Repository (To be released soon)
- R Package Github Repository
- Workshop Github Repository
Functionality
The main goal of the Geodata-Harvester is to enable researchers with reusable workflows for automatic data extraction and processing:
- Retrieve: automatically access geo-spatial and soil data sources, minimal handling of individual APIs
- Process: Spatial and temporal processing, filter, mask, reduce and convert data
- Output: download data as GeoTIFF and ready-made data frames for use in additional modelling and machine learning workflows
Geodata-Harvester is designed as a modular and maintainable project in the form of a multi-stage pipeline by providing explicit boundaries among tasks. To encourage interaction and experimentation with the pipeline, we provide multiple frontend notebooks and use case scenarios as Jupyter and R notebooks, as well as standalone Python and R packages. The core features are:
- automatic data retrieval from geo-spatial APIs for given locations and dates
- data experimentation front-ends via Jupyter and R notebooks
- enables reusable workflows via interactive widgets and YAML files to save/load settings.
- automatic geo-spatial-temporal processing
- support for multiple temporal aggregation options
- automatic extraction of retrieved data into ready-made dataframes for Machine Learning models
- data visualisation
- preview of data map layers (for GEE layers)
- support for cloud-masking of satellite data (for GEE layers)

Project Details
Project Deliverables
- Python software package with tools for data aggregation and processing
- Python Jupyter notebook
- R notebook
- Documentation of package including functionality and installation
- Examples and use-case scenarios
- Training workshop
Recording of Python GeoData Harvester Workshop:
Project Phase I (Completed)
As part of the first stage of the project, a prototype of the Data Harvester has been developed and successfully tested for automatic retrieval and processing of multiple layers including soil, climate, satellite, and terrain data. The first use case scenario (static) has been tested on L’Lara. The next project stage will focus on adding more data layers and methods, user settings, and temporal processing functionalities.
The goal of the Data Harvester prototype was to demonstrate the core functionalities of data retrieval and processing for a selected range of data sources, and its feasibility by testing on a use-case scenario (here for the L’llara dataset). The development and results of the prototype guided the design process for the final Data Harvester software.
Project Phase II (Completed)
The goal of the second development phase is to develop an open-source software package which includes multiple additional data and feature improvements:
- Support for multiple temporal aggregation options
- Additional data sources: radiometric and landscape data
- Integration of Google Earth Engine data sources and processing such as cloud-masking and calculation of multiple spectral index products (e.g., NDVI)
- Improved user input setting selection via interactive notebook widgets
- Development of R packages and notebooks to make Harvester more useable by broadening to R user base
- Preparation and delivery of training documentations and workshops
Publication
Haan et al., (2023). Geodata-Harvester: A Python package to jumpstart geospatial data extraction and analysis. Journal of Open Source Software, 8(89), 5205, https://doi.org/10.21105/joss.05205
If you make use of this software for your research project, please cite this paper or include the following acknowledgment: “This research was supported by the Sydney Informatics Hub, a Core Research Facility of the University of Sydney, and the Agricultural Research Federation (AgReFed).” AgReFed is supported by the Australian Research Data Commons (ARDC) and the Australian Government through the National Collaborative Research Infrastructure Strategy (NCRIS)
